Okvir NVIDIA NeMo

Specifikacije
- Ime izdelkaOgrodje NVIDIA NeMo
- Zadevne platforme: Windows, Linux, macOS
- Prizadete različice: Vse različice pred 24.
- Varnostna ranljivost: CVE-2025-23360
- Osnovna ocena tveganja: 7.1 (CVSS različica 3.1)
Navodila za uporabo izdelka
Namestitev varnostne posodobitve:
Za zaščito sistema sledite tem korakom:
- Najnovejšo izdajo lahko prenesete s strani z izdajami NeMo-Framework-Launcher na GitHubu.
- Za več informacij obiščite Varnost izdelkov NVIDIA.
Podrobnosti o varnostni posodobitvi:
Varnostna posodobitev odpravlja ranljivost v ogrodju NVIDIA NeMo, ki bi lahko povzročila izvajanje kode in uhajanje podatkov.ampering.
Nadgradnja programske opreme:
Če uporabljate starejšo izdajo veje, je priporočljivo, da nadgradite na najnovejšo izdajo veje, da odpravite varnostno težavo.
konecview
Okvir NVIDIA NeMo je skalabilen in v oblaku zasnovan generativni okvir umetne inteligence, zgrajen za raziskovalce in razvijalce, ki delajo na Veliki jezikovni modeli, multimodalni in Govorna umetna inteligenca (npr Samodejno prepoznavanje govora in Pretvorba besedila v govor). Uporabnikom omogoča učinkovito ustvarjanje, prilagajanje in uvajanje novih generativnih modelov umetne inteligence z izkoriščanjem obstoječe kode in predhodno naučenih kontrolnih točk modelov.
Navodila za namestitev: Namestitev ogrodja NeMo
Ogrodje NeMo zagotavlja celovito podporo za razvoj modelov velikih jezikov (LLM) in multimodalnih modelov (MM). Zagotavlja prilagodljivost za uporabo na lokaciji, v podatkovnem centru ali pri vašem izbranem ponudniku storitev v oblaku. Podpira tudi izvajanje v okoljih, ki podpirajo SLURM ali Kubernetes.

Kuriranje podatkov
NeMo kurator [1] je knjižnica Python, ki vključuje nabor modulov za podatkovno rudarjenje in generiranje sintetičnih podatkov. So skalabilni in optimizirani za grafične procesorje, zaradi česar so idealni za kuriranje podatkov naravnega jezika za učenje ali fino nastavitev LLM-jev. Z NeMo Curatorjem lahko učinkovito izvlečete visokokakovostno besedilo iz obsežnih surovih podatkov. web viri podatkov.
Usposabljanje in prilagajanje
NeMo Framework ponuja orodja za učinkovito učenje in prilagajanje LLM in multimodalne modele. Vključuje privzete konfiguracije za nastavitev računalniškega grozda, prenos podatkov in hiperparametre modela, ki jih je mogoče prilagoditi za učenje na novih naborih podatkov in modelih. Poleg predhodnega učenja NeMo podpira tako tehnike nadzorovanega natančnega uglaševanja (SFT) kot tudi tehnike parametrično učinkovitega natančnega uglaševanja (PEFT), kot so LoRA, Ptuning in druge.
Za zagon usposabljanja v NeMo sta na voljo dve možnosti – z uporabo vmesnika NeMo 2.0 API ali z NeMo Run.
- Z NeMo Run (priporočeno): NeMo Run ponuja vmesnik za poenostavitev konfiguracije, izvajanja in upravljanja eksperimentov v različnih računalniških okoljih. To vključuje zagon opravil na vaši delovni postaji lokalno ali v velikih gručah – tako z omogočenim SLURM kot Kubernetes v oblačnem okolju.
- Predvadbeni trening in hitri začetek PEFT z NeMo Run
- Uporaba API-ja NeMo 2.0: Ta metoda deluje dobro pri preprostih nastavitvah, ki vključujejo majhne modele, ali če vas zanima pisanje lastnega nalagalnika podatkov, učnih zank ali spreminjanje plasti modela. Omogoča vam večjo prilagodljivost in nadzor nad konfiguracijami ter omogoča enostavno programsko razširjanje in prilagajanje konfiguracij.
-
traHitri začetek z NeMo 2.0 API-jem
-
Selitev iz NeMo 1.0 na NeMo 2.0 API
-
Poravnava
- NeMo-Poravnalnik [1] je prilagodljiv komplet orodij za učinkovito poravnavo modelov. Komplet orodij podpira najsodobnejše algoritme za poravnavo modelov, kot so SteerLM, DPO, učenje z okrepitvijo iz človeških povratnih informacij (RLHF) in še veliko več. Ti algoritmi uporabnikom omogočajo poravnavo jezikovnih modelov, da so varnejši, neškodljivi in koristnejši.
- Vse kontrolne točke NeMo-Aligner so navzkrižno združljive z ekosistemom NeMo, kar omogoča nadaljnje prilagajanje in uvajanje sklepanja.
Postopni potek vseh treh faz RLHF na majhnem modelu GPT-2B:
- Usposabljanje za SFT
- Usposabljanje za model nagrajevanja
- Usposabljanje za javno naročilo
Poleg tega podpiramo različne druge nove metode poravnave:
- DPO: lahek algoritem poravnave v primerjavi z RLHF z enostavnejšo funkcijo izgub.
- Samostojna igra Fina nastavitev (SPIN)
- SteerLM: tehnika, ki temelji na pogojeni SFT, z vodljivim izhodom.
Za več informacij si oglejte dokumentacijo: Dokumentacija o poravnavi
Multimodalni modeli
- Okvir NeMo ponuja optimizirano programsko opremo za učenje in uvajanje najsodobnejših multimodalnih modelov v več kategorijah: modeli multimodalnega jezika, osnove vizualnega jezika, modeli pretvorbe besedila v sliko in več kot 2D-generacija z uporabo polj nevronskega sevanja (NeRF).
- Vsaka kategorija je zasnovana tako, da zadosti specifičnim potrebam in napredku na tem področju, pri čemer izkorišča najsodobnejše modele za obdelavo širokega nabora vrst podatkov, vključno z besedilom, slikami in 3D-modeli.
Opomba
Podporo za multimodalne modele selimo iz različice NeMo 1.0 v NeMo 2.0. Če želite medtem raziskati to področje, si oglejte dokumentacijo za izdajo NeMo 24.07 (prejšnja).
Uvajanje in sklepanje
Okvir NeMo ponuja različne poti za sklepanje LLM, ki ustrezajo različnim scenarijem uvajanja in potrebam po zmogljivosti.
Uvajanje z NVIDIA NIM
- Okvir NeMo se brezhibno integrira z orodji za uvajanje modelov na ravni podjetja prek NVIDIA NIM. To integracijo poganja NVIDIA TensorRT-LLM, kar zagotavlja optimizirano in skalabilno sklepanje.
- Za več informacij o NIM obiščite spletno stran NVIDIA. webmesto.
Uvajanje s TensorRT-LLM ali vLLM
- Ogrodje NeMo ponuja skripte in API-je za izvoz modelov v dve knjižnici, optimizirani za sklepanje, TensorRT-LLM in vLLM, ter za uvajanje izvoženega modela s strežnikom za sklepanje NVIDIA Triton.
- Za scenarije, ki zahtevajo optimizirano delovanje, lahko modeli NeMo izkoristijo TensorRT-LLM, specializirano knjižnico za pospeševanje in optimizacijo sklepanja LLM na grafičnih procesorjih NVIDIA. Ta postopek vključuje pretvorbo modelov NeMo v obliko, združljivo s TensorRT-LLM, z uporabo modula nemo.export.
- Uvedba LLM je končanaview
- Uvedite velike jezikovne modele NeMo z NIM
- Uvajanje velikih jezikovnih modelov NeMo s TensorRT-LLM
- Uvajanje velikih jezikovnih modelov NeMo z vLLM
Podprti modeli
Veliki jezikovni modeli
| Veliki jezikovni modeli | Predhodni trening in SFT | PEFT | Poravnava | Konvergenca usposabljanja v 8. okvirnem programu | TRT/TRTLLM | Pretvori v in iz objemajočega obraza | Evalvacija |
|---|---|---|---|---|---|---|---|
| Lama3 8B/70B, Lama3.1 405B | ja | ja | x | Da (delno preverjeno) | ja | Oba | ja |
| Mixtral 8x7B/8x22B | ja | ja | x | Da (nepreverjeno) | ja | Oba | ja |
| Nemotron 3 8B | ja | x | x | Da (nepreverjeno) | x | Oba | ja |
| Nemotron 4 340B | ja | x | x | Da (nepreverjeno) | x | Oba | ja |
| Baichuan2 7B | ja | ja | x | Da (nepreverjeno) | x | Oba | ja |
| KlepetGLM3 6B | ja | ja | x | Da (nepreverjeno) | x | Oba | ja |
| Gemma 2B/7B | ja | ja | x | Da (nepreverjeno) | ja | Oba | ja |
| Gemma2 2B/9B/27B | ja | ja | x | Da (nepreverjeno) | x | Oba | ja |
| Mamba2 130M/370M/780M/1.3B/2.7B/8B/ Hybrid-8B | ja | ja | x | Da (nepreverjeno) | x | x | ja |
| Phi3 mini 4k | x | ja | x | Da (nepreverjeno) | x | x | x |
| Qwen2 0.5B/1.5B/7B/72B | ja | ja | x | Da (nepreverjeno) | ja | Oba | ja |
| StarCoder 15B | ja | ja | x | Da (nepreverjeno) | ja | Oba | ja |
| StarCoder2 3B/7B/15B | ja | ja | x | Da (nepreverjeno) | ja | Oba | ja |
| BERT 110M/340M | ja | ja | x | Da (nepreverjeno) | x | Oba | x |
| T5 220M/3B/11B | ja | ja | x | x | x | x | x |
Modeli vizualnega jezika
| Modeli vizualnega jezika | Predhodni trening in SFT | PEFT | Poravnava | Konvergenca usposabljanja v 8. okvirnem programu | TRT/TRTLLM | Pretvori v in iz objemajočega obraza | Evalvacija |
|---|---|---|---|---|---|---|---|
| NeVA (LLaVA 1.5) | ja | ja | x | Da (nepreverjeno) | x | Od | x |
| Lama 3.2 Vision 11B/90B | ja | ja | x | Da (nepreverjeno) | x | Od | x |
| LLaVA Naprej (LLaVA 1.6) | ja | ja | x | Da (nepreverjeno) | x | Od | x |
Vdelava modelov
| Vdelava jezikovnih modelov | Predhodni trening in SFT | PEFT | Poravnava | Konvergenca usposabljanja v 8. okvirnem programu | TRT/TRTLLM | Pretvori v in iz objemajočega obraza | Evalvacija |
|---|---|---|---|---|---|---|---|
| SBERT 340M | ja | x | x | Da (nepreverjeno) | x | Oba | x |
| Lama 3.2 Vdelava 1B | ja | x | x | Da (nepreverjeno) | x | Oba | x |
Modeli svetovnih fundacij
| Modeli svetovnih fundacij | Po usposabljanju | Pospešeno sklepanje |
|---|---|---|
| Cosmos-1.0-Diffusion-Text2World-7B | ja | ja |
| Cosmos-1.0-Diffusion-Text2World-14B | ja | ja |
| Cosmos-1.0-Diffusion-Video2World-7B | Kmalu na voljo | Kmalu na voljo |
| Cosmos-1.0-Diffusion-Video2World-14B | Kmalu na voljo | Kmalu na voljo |
| Cosmos-1.0-Avtoregresivna-4B | ja | ja |
| Cosmos-1.0-Avtoregresivna-Video2World-5B | Kmalu na voljo | Kmalu na voljo |
| Cosmos-1.0-Avtoregresivna-12B | ja | ja |
| Cosmos-1.0-Avtoregresivna-Video2World-13B | Kmalu na voljo | Kmalu na voljo |
Opomba
NeMo podpira tudi predučenje za difuzijsko in avtoregresivno arhitekturo text2world modeli temeljev.
Govorna umetna inteligenca
Razvoj pogovornih modelov umetne inteligence je kompleksen proces, ki vključuje definiranje, konstruiranje in učenje modelov znotraj določenih domen. Ta proces običajno zahteva več iteracij za doseganje visoke stopnje natančnosti. Pogosto vključuje več iteracij za doseganje visoke natančnosti, fino nastavitev različnih nalog in podatkov, specifičnih za domeno, zagotavljanje učinkovitosti učenja in pripravo modelov za uvajanje sklepanja.
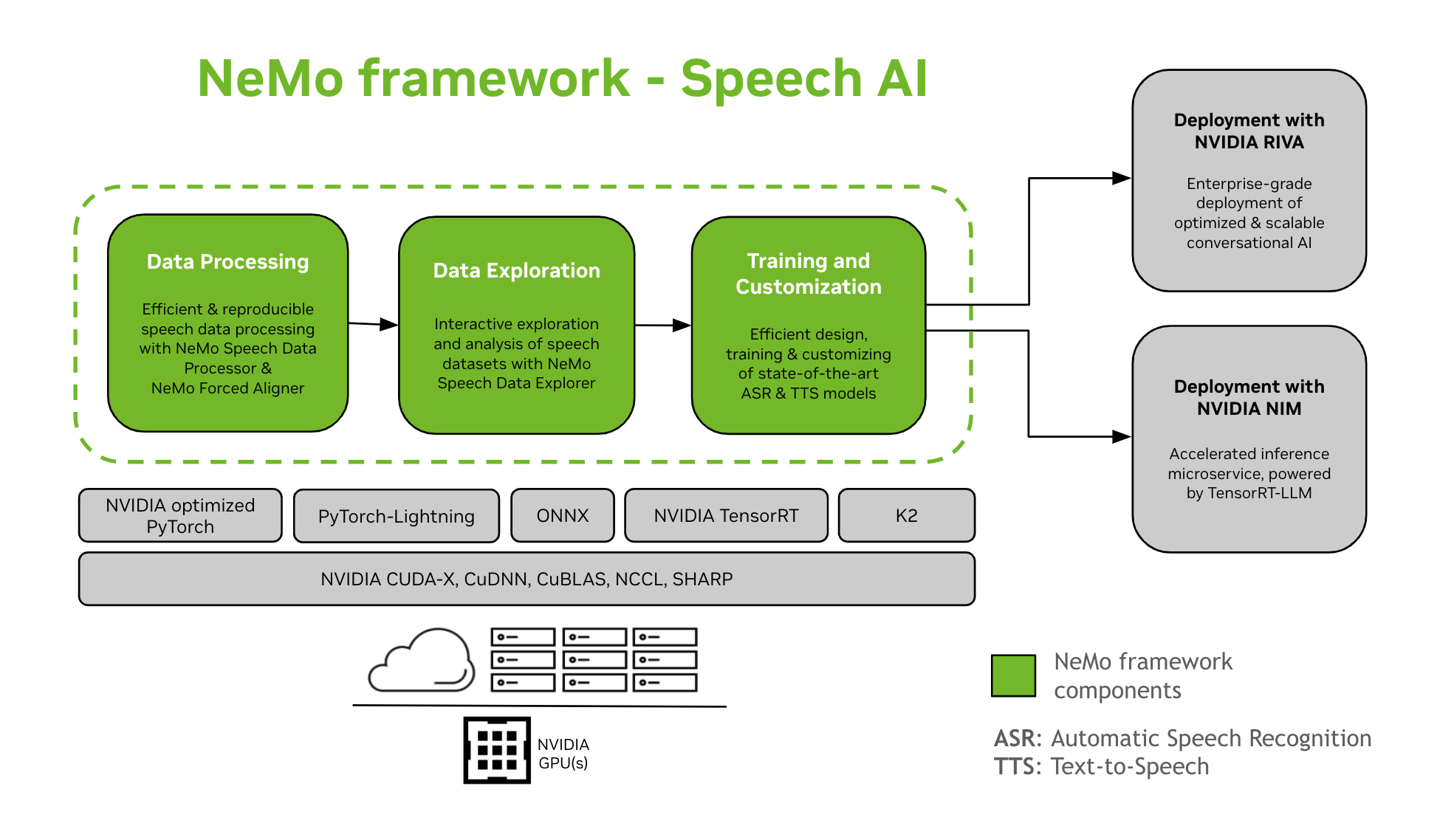
Ogrodje NeMo nudi podporo za učenje in prilagajanje modelov govorne umetne inteligence. To vključuje naloge, kot sta samodejno prepoznavanje govora (ASR) in sinteza besedila v govor (TTS). Z NVIDIA Riva ponuja nemoten prehod na produkcijsko uvajanje na ravni podjetja. V pomoč razvijalcem in raziskovalcem ogrodje NeMo vključuje najsodobnejše predhodno naučene kontrolne točke, orodja za ponovljivo obdelavo govornih podatkov in funkcije za interaktivno raziskovanje in analizo govornih naborov podatkov. Komponente ogrodja NeMo za govorno umetno inteligenco so naslednje:
Usposabljanje in prilagajanje
Okvir NeMo vsebuje vse, kar je potrebno za učenje in prilagajanje govornih modelov (ASR, Klasifikacija govora, Prepoznavanje govorcev, Dnevnik govorca, in TTS) na ponovljiv način.
Predhodno izurjeni modeli SOTA
- NeMo Framework ponuja najsodobnejše recepte in vnaprej naučene kontrolne točke več ASR in TTS modele, kot tudi navodila za njihovo nalaganje.
- Govorna orodja
- Okvir NeMo ponuja nabor orodij, uporabnih za razvoj modelov ASR in TTS, vključno z:
- NeMo prisilni poravnalnik (NFA) za generiranje časovnih meritev na ravni žetonov, besed in segmentovampgovora v zvoku z uporabo NeMo-jevih modelov samodejnega prepoznavanja govora, ki temeljijo na CTC.
- Procesor govornih podatkov (SDP), komplet orodij za poenostavitev obdelave govornih podatkov. Omogoča vam predstavitev operacij obdelave podatkov v konfiguraciji file, kar zmanjšuje količino standardne kode in omogoča ponovljivost ter deljenje.
- Raziskovalec govornih podatkov (SDE), ki temelji na Dashu web aplikacija za interaktivno raziskovanje in analizo govornih naborov podatkov.
- Orodje za ustvarjanje naborov podatkov ki omogoča poravnavo dolgega zvoka filez ustreznimi transkripti in jih razdeli na krajše fragmente, ki so primerni za učenje modela samodejnega prepoznavanja govora (ASR).
- Orodje za primerjavo za modele ASR za primerjavo napovedi različnih modelov ASR na ravni natančnosti besed in izgovorjave.
- Ocenjevalec ASR za ocenjevanje delovanja modelov ASR in drugih funkcij, kot je zaznavanje glasovne aktivnosti.
- Orodje za normalizacijo besedila za pretvorbo besedila iz pisane v govorjeno obliko in obratno (npr. »31.« proti »enajstintrideseti«).
- Pot do uvedbe
- Modele NeMo, ki so bili usposobljeni ali prilagojeni z uporabo ogrodja NeMo, je mogoče optimizirati in namestiti z NVIDIA Rivo. Riva ponuja vsebnike in Helm grafikone, posebej zasnovane za avtomatizacijo korakov za nameščanje s pritiskom na gumb.
Drugi viri
- NeMoGlavno skladišče za ogrodje NeMo
- NeMo–TečiOrodje za konfiguriranje, zagon in upravljanje eksperimentov strojnega učenja.
- NeMo-Poravnalnik: Prilagodljiv komplet orodij za učinkovito poravnavo modelov
- NeMo-kurator: Prilagodljiv komplet orodij za predobdelavo in kuriranje podatkov za LLM
Sodelujte s skupnostjo NeMo, postavljajte vprašanja, poiščite podporo ali prijavite napake.
- Razprave o NeMo
- Težave NeMo
Programski jeziki in ogrodja
- PythonGlavni vmesnik za uporabo ogrodja NeMo
- PytorchOkvir NeMo je zgrajen na PyTorchu
Licence
- Repozitorij NeMo Github je licenciran pod licenco Apache 2.0.
- NeMo Framework je licenciran v skladu s POGODBO O IZDELKU NVIDIA AI. Z uporabo vsebnika sprejemate določila in pogoje te licence.
- Vsebnik NeMo Framework vsebuje gradiva Llama, ki jih ureja licenčna pogodba skupnosti Meta Llama3.
Opombe
Trenutno je podpora za NeMo Curator in NeMo Aligner za multimodalne modele v teku in bo kmalu na voljo.
pogosta vprašanja
V: Kako lahko preverim, ali je moj sistem prizadet zaradi ranljivosti?
A: Ali je vaš sistem prizadet, lahko preverite tako, da preverite različico nameščenega ogrodja NVIDIA NeMo Framework. Če je starejša od različice 24, je vaš sistem morda ranljiv.
V: Kdo je prijavil varnostno težavo CVE-2025-23360?
A: Varnostno težavo je prijavil Or Peles – JFrog Security. NVIDIA se zahvaljuje njihovemu prispevku.
V: Kako lahko prejemam prihodnja obvestila o varnostnih biltenih?
O: Obiščite stran Varnost izdelkov NVIDIA, če se želite naročiti na obvestila o varnostnih biltenih in ostati obveščeni o varnostnih posodobitvah izdelkov.
Dokumenti / Viri
 |
Okvir NVIDIA NeMo [pdf] Uporabniški priročnik Okvir NeMo, NeMo, Okvir |